Kali Study Diary
2016/9/6
For study how to using Kali to doing penetration test, I'm plan to following the book "Mastering-Kali-Linux-for-Advanced-Penetration-Testing", step by step practice those attacking skill.
first, is build up the Kali Lab environments, I've setup two Kali system, one is running on VirtualBox VM, and the other is on USB for portable.
1. Download Kali system image including VM and USB version from official website.
2. Install Kali VM on my Windows 10 laptop
3. Install Kali bootable USB image on 16G USB flash drive, and config rest of free space to join in persistence environment.
After Kali is installed and running, doing system update as following commands:
#apt-get update
#apt-get upgrade -y
#apt-get dist-upgrade -y
and put those commands in upgrade.sh script file.
Customization make to Kali:
1. Resetting the root password
#passwd root
2. Adding a non-root user
#adduser nonroot
3. Truecrypt is no longer bundled with Kali. Many users recommend use Veracrypt instead. I don't need it right now, so skip it.
4. Installing third-party applications
#apt-get install apt-file
#apt-get install scrub
#apt-get install shutter
#apt-get terminator
5. skip those applications, teamviewer, openoffice, istanbul, gnome-tweak-tool
Management tools of penetration test, classify in Application -> Reporting Tools, such as dradis, magictree and cutycapt etc.
2016年9月7日 星期三
2016年7月8日 星期五
Eric Clapton – River Of Tears
It's three miles to the river
That would carry me away
Two miles to the dusty street
That I saw you on today.
It's four miles to my lonely room
Where I will hide my face
And about half a mile to the downtown bar
That I ran from in disgrace.
Lord how long have I got to keep on running
Seven hours seven days or seven years?
All I know is since you've been gone
I feel like I'm drowning in a river,
Drowning in a river of tears.
Drowning in a river.
Feel like I'm drowning,
Drowning in a river.
In three more days, I'll leave this town
And disappear without a trace.
A year from now, maybe settle down
Where no one knows my face.
I wish that I could hold you
One more time to ease the pain,
But my time's run out and I got to go,
Got to run away again.
Still I catch myself thinking,
One day I'll find my way back here.
You'll save me from drowning,
Drowning in a river,
Drowning in a river of tears.
Drowning in a river.
Feels like I'm drowning,
Drowning in the river.
Lord, how long must this go on?
Drowning in a river,
Drowning in a river of tears.
Songwriters: CLAPTON, ERIC PATRICK/CLIMIE, SIMON CRISPIN
River Of Tears lyrics © Warner/Chappell Music, Inc.
2016年7月6日 星期三
3GPP公開5G標準化路線圖
轉貼文章
移動通信標準化團體3GPP (Third Generation Partnership Project)2016年6月27日宣布,“3GPP技術規範組”(3GPP Technical Specifications Groups,TSG#72)已就5G標準的首個版本——Release 15的詳細工作計劃達成一致。該計劃記述了各工作組的協調項目和檢查重點,並明確Release 15的5G相關規範將於2018年6月確定。Release15的5G標準化計劃表(摘自3GPP的網站) (點擊放大)3GPP TSG RAN方面,關於Release 15的5G New Radio(NR)調查範圍,技術規範組一致同意對獨立(Stand-alone,只使用5G)和非獨立(同時使用LTE環境和NR)兩種架構提供支持。而且,還同時確定了目標用例和目標頻帶,目標用例為增強型移動寬帶(Enhanced Mobile Broadband,eMBB)和要求低延遲、高可靠性的Ultra-Reliable and Low Latency Communications(URLCC)領域,目標頻帶為低於6GH和高於6GHz的範圍。另外,TSG#72還在討論時強調,要想發布5G標準,無線與協議兩方面的設計具有向上兼容性是分階段導入功能和考慮實現各個用例時的關鍵點。(特約撰稿人:加藤樹子)


移動通信標準化團體3GPP (Third Generation Partnership Project)2016年6月27日宣布,“3GPP技術規範組”(3GPP Technical Specifications Groups,TSG#72)已就5G標準的首個版本——Release 15的詳細工作計劃達成一致。該計劃記述了各工作組的協調項目和檢查重點,並明確Release 15的5G相關規範將於2018年6月確定。Release15的5G標準化計劃表(摘自3GPP的網站) (點擊放大)3GPP TSG RAN方面,關於Release 15的5G New Radio(NR)調查範圍,技術規範組一致同意對獨立(Stand-alone,只使用5G)和非獨立(同時使用LTE環境和NR)兩種架構提供支持。而且,還同時確定了目標用例和目標頻帶,目標用例為增強型移動寬帶(Enhanced Mobile Broadband,eMBB)和要求低延遲、高可靠性的Ultra-Reliable and Low Latency Communications(URLCC)領域,目標頻帶為低於6GH和高於6GHz的範圍。另外,TSG#72還在討論時強調,要想發布5G標準,無線與協議兩方面的設計具有向上兼容性是分階段導入功能和考慮實現各個用例時的關鍵點。(特約撰稿人:加藤樹子)
2016年6月19日 星期日
June 19, 2016
清晨五點不到,天就濛濛亮了,幾天來已經習慣在天光明暗變化中,轟隆呼嘯的車流聲中清醒,窗外的天空透著淡藍,風微凉,想必今天應該是個陽光普照的好天氣。
北上後的第一個周末,出門拜訪這個曾經熟悉的陌生社區。30年,記憶中的稻田已被一棟棟的高樓取代,小吃店、美式速食、連鎖超商、小型賣場,甚至近年來通車的捷運,將這個由學生、藍領勞工撐起的小社區,蛻變成今日的繁華容貌。
漫遊在陌生的舊街上,試圖搜尋那記憶中曾經熟悉的映像,無奈歲月的長河已將記憶沖淡,也或許彼時就不曾烙刻在腦海中,怎樣也想不起曾經有過的那段青春歲月。當年,播放港劇的自助餐如今變成全家超商,一整排老舊的透天厝哪戶曾是昔日社團聚會的租屋,已不復記憶。忽然想起曾有個冬日微雨的夜晚,在街邊小攤上喝著紅豆湯、隨身聽放著梅艷芳的卡帶,好像是bad girl又或是烈火紅脣,對面雜貨店賣著常抽的More、Salem、Parliament,......。2年的生活記事只剩殘影片段。
隔著一條省道,對面就是生活2年的學校。今天校門附近有著周末不尋常的人潮,騎樓旁滿是賣著漂亮花束的小販,直覺的判斷今日應該是畢業典禮吧! 走進30年前離開後未曾再踏進的校門,感覺就跟身旁那些畢業生家長一樣的新鮮。學校傍山而建,龍華坡走起來還是令人汗流浹背。當初的二專已搖身升格為技術大學,校園多了些建築,整體的景觀也變漂亮了。隨意走了一遍,圖書館、頂樓操場、學生宿舍都還記得,但當初上課做實習的教室,已不知迷失在哪棟大樓中。
校園裡隨處可見穿著學士服的畢業生,笑容燦爛地跟家長或同學留影。從他們身旁走過,幻想著哪個是曾經的自己,回神後才驚然,當年畢業典禮的情境怎麼也想不起來,只記得站在教室走廊上身穿校服的自己,手中拿著畢業證書跟紀念冊,當時是興奮? 是茫然? 是離愁? 已不可追憶。
北上後的第一個周末,出門拜訪這個曾經熟悉的陌生社區。30年,記憶中的稻田已被一棟棟的高樓取代,小吃店、美式速食、連鎖超商、小型賣場,甚至近年來通車的捷運,將這個由學生、藍領勞工撐起的小社區,蛻變成今日的繁華容貌。
漫遊在陌生的舊街上,試圖搜尋那記憶中曾經熟悉的映像,無奈歲月的長河已將記憶沖淡,也或許彼時就不曾烙刻在腦海中,怎樣也想不起曾經有過的那段青春歲月。當年,播放港劇的自助餐如今變成全家超商,一整排老舊的透天厝哪戶曾是昔日社團聚會的租屋,已不復記憶。忽然想起曾有個冬日微雨的夜晚,在街邊小攤上喝著紅豆湯、隨身聽放著梅艷芳的卡帶,好像是bad girl又或是烈火紅脣,對面雜貨店賣著常抽的More、Salem、Parliament,......。2年的生活記事只剩殘影片段。
隔著一條省道,對面就是生活2年的學校。今天校門附近有著周末不尋常的人潮,騎樓旁滿是賣著漂亮花束的小販,直覺的判斷今日應該是畢業典禮吧! 走進30年前離開後未曾再踏進的校門,感覺就跟身旁那些畢業生家長一樣的新鮮。學校傍山而建,龍華坡走起來還是令人汗流浹背。當初的二專已搖身升格為技術大學,校園多了些建築,整體的景觀也變漂亮了。隨意走了一遍,圖書館、頂樓操場、學生宿舍都還記得,但當初上課做實習的教室,已不知迷失在哪棟大樓中。
校園裡隨處可見穿著學士服的畢業生,笑容燦爛地跟家長或同學留影。從他們身旁走過,幻想著哪個是曾經的自己,回神後才驚然,當年畢業典禮的情境怎麼也想不起來,只記得站在教室走廊上身穿校服的自己,手中拿著畢業證書跟紀念冊,當時是興奮? 是茫然? 是離愁? 已不可追憶。
{kind=link}
 |
| 學校入口的牌樓 |
 |
| 各式特色造型的花束 |
 |
| 實際的校園,還要爬上這段陡坡 |
 |
| 校園一隅 |
 |
| 昔日的學生宿舍,如今依然如樣 |
 |
| 禮堂 |
 |
| 畢業典禮的開場表演 |
 |
| 坐落在樓頂的運動場 |
 |
| 校園一隅 |
 |
| 校園一隅 |
 |
| 校園內的伯朗咖啡 |
 |
| 舊街區 |
 |
| 早晨舊街市場,兩旁擺滿攤販 |
 |
| 昔日的自助餐店已變成便利超商 |
 |
| 舊街市場 |
 |
| 30年前曾租屋於此,猶記當時還是新落成的樓排,今日已成老厝 |
2016年6月12日 星期日
鉛灰的天空,一如我對台北城一貫的映象,相隔四年後,我重返這座城市。
昨天是端午連假的第三天,經濟考量,選擇搭客運北上,出發時屏東下著滂沱大雨,雨終有停時,而此時心中已下了好幾年的陰雨何時能有放晴的一日?
這次感謝妹的幫忙,幫我介紹工作、經濟資助、張羅住處、打點雜七雜八的生活用品等,若沒有她,我或許沒有勇氣再重新生活,畢竟所謂的朋友早已遠離,幾十年的老同學也只剩吃飯打屁的交情,可歎人情如此。
中午跟Dean約好在西門町碰面,幾年不見了,發現蒼老了許多,或許自己容貌也多有變化,只是未發現罷了。
吃飯、喝咖啡、聊天、無目的的路上閑晃,雖相隔多年未見,但重相聚後那種親切與熟悉卻未曾改變,這讓我在這陌生的城市又多了一絲溫暖。
回到租處,傍晚的天空已下起小雨,未來的路該如何走,茫然無措。該如何面對明日重新開始的職場生活,依然毫無準備。
昨天是端午連假的第三天,經濟考量,選擇搭客運北上,出發時屏東下著滂沱大雨,雨終有停時,而此時心中已下了好幾年的陰雨何時能有放晴的一日?
這次感謝妹的幫忙,幫我介紹工作、經濟資助、張羅住處、打點雜七雜八的生活用品等,若沒有她,我或許沒有勇氣再重新生活,畢竟所謂的朋友早已遠離,幾十年的老同學也只剩吃飯打屁的交情,可歎人情如此。
中午跟Dean約好在西門町碰面,幾年不見了,發現蒼老了許多,或許自己容貌也多有變化,只是未發現罷了。
吃飯、喝咖啡、聊天、無目的的路上閑晃,雖相隔多年未見,但重相聚後那種親切與熟悉卻未曾改變,這讓我在這陌生的城市又多了一絲溫暖。
回到租處,傍晚的天空已下起小雨,未來的路該如何走,茫然無措。該如何面對明日重新開始的職場生活,依然毫無準備。
2015年3月15日 星期日
Lightroom 重新安裝 / 重要檔案備份
編目(Catalog)
系統預設的目錄:
Windows—C: \ Users \ [your username] \ My Pictures \ Lightroom \ Lightroom 5 Catalog. lrcat
Mac—Macintosh HD / Users / [your username] / Pictures / Lightroom / Lightroom 5 Catalog. lrcat
在實務上,通常會依照片管理的方便性建立多個編目,而且會指定到其他的儲存媒體上,例如D槽、E槽或外接硬碟等。記得所有的編目都要保存下來,一併轉移到新系統上。
查詢編目存放的路徑可以從Lightroom工具列的[編輯]-->[編目設定]查看設定目錄位置

預視
( Preview) 及智慧型預視( Smart Preview)
智慧型預視的檔案大小比原始相片小很多。通常選擇將原始相片保存於高容量的外接硬碟 (例如 NAS 裝置或外接式硬碟),藉此釋放儲存容量較小之裝置的磁碟空間 (例如 SSD 固態硬碟)
系統預設的預視及智慧型預視儲存目錄:
< 編目名稱 > Previews.lrdata , (與編目位於同一個檔案夾)
< 編目名稱 > Smart Previews. lrdata , (與編目位於同一個檔案夾)
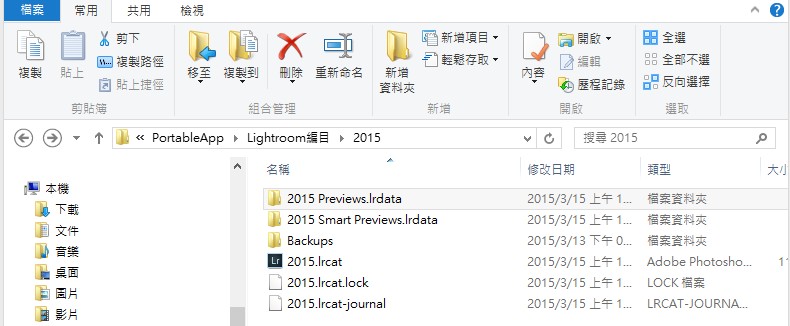
編目備份
( Catalog Backup)
編目備份檔案預設儲存於 Backups 檔案夾。備份檔案會放在以備份執行日期和時間命名的檔案夾中,預設的儲存位置與與編目位於同一個檔案夾。(參考上圖)
不過,備份檔案的位置可能會有變更,最好在「備份編目」對話框中,按一下「備份檔案夾」路徑旁的「選擇」,確認檔案位置。

當然,既然是備份,要不要一併轉移到新系統上,就看個人需要了。
照片(Photos)
這應該不用特別說明,不過這是指從相機記憶卡匯入存放的位置。
預設集
( Presets & Templates)
系統預設的存放位置::
Windows—C: \ Users \ [your username] \ AppData \ Roaming \ Adobe \ Lightroom \
Mac—Macintosh HD / Users / [your username] / Library / Application Support / Adobe / Lightroom /
另外,與Camera Raw共用的設定如:Default Settings, Point Curves, Custom Camera & Lens Profiles,預設存放位置::
Windows—C: \ Users \ [your username] \ AppData \ Roaming \ Adobe \ CameraRaw \
Mac—Macintosh HD / Users / [your username] / Library / Application Support / Adobe / CameraRaw /
Plug-ins
如果有安裝插件(Plug-in)的話,記得把插件安裝的目錄、版本、序號等記錄下來。可以從工具列的[檔案]-->[增效模組管理員]查詢。
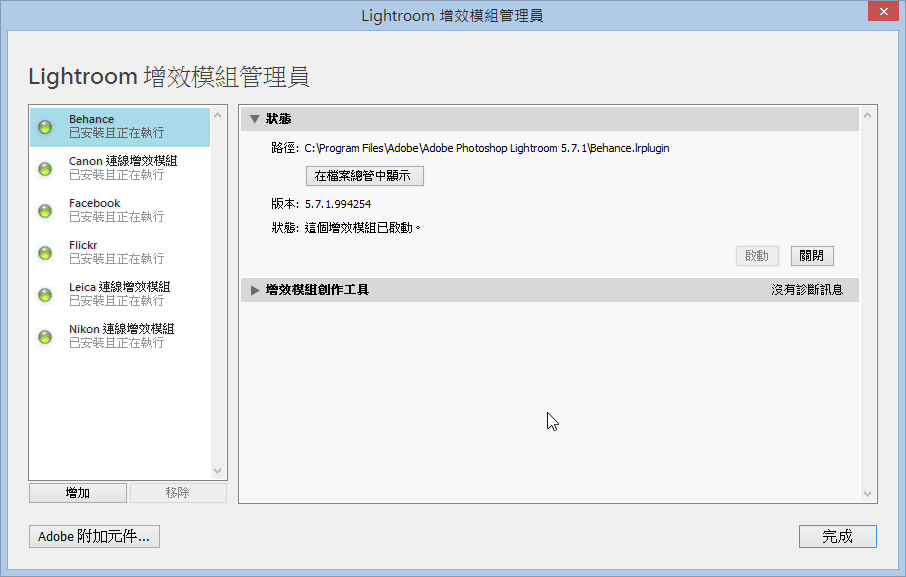
Lightroom 序號
偏好設定(Preferences)
紀錄Lightroom的個人設定,甚至最後的使用紀錄等。預設的存放位置在:
Windows—C: \ Users \ [your username] \ AppData \ Roaming \ Adobe \ Lightroom \ Preferences \ Lightroom 5 Preferences. agprefs
Mac—Macintosh HD / Users / [your username] / Library / Preferences / com . adobe. Lightroom5. plist
2014年5月15日 星期四
認識 Hadoop Clusters 基本運作與網路架構的關聯性
這是一篇談到Hadoop核心構件運作原理與網路架構的文章 Understanding Hadoop Clusters and the Network,摘要其重點內容。

Hadoop架構中的主機伺服器
Hadoop架構中主機可區分為3類:Client machines, Masters nodes, and Slave nodes。- Masters nodes包含Hadoop架構中最重要的2項功能:存儲大量數據(HDFS),以及平行運算所儲存的數據(Map Reduce)。Name Node負責監督和協調數據存儲功能(HDFS),而Jab Tracker(YARN:Map/Reduce 2中則稱為 Resource Manager)負責監督和協調Map Reduce對數據的並行處理。
- 其餘大部分的主機則屬於Slave Node,每個Slave Node同時執行Data Node及Task Tracker(YARN:Map/Reduce 2中稱為 Node Manager)Daemon,Data Node接收來自Name Node的指揮,負責實際資料的儲存,而Task Tracker則接收來自Jab Tracker的指揮,負責Map Reduce的資料運算處理。
- 安裝Hadoop軟體的Client主機,則負責向 Name Node提出將數據載入到Cluster的需求,以及向Job Tracker提出Map/Reducem運算需求,並接收及檢視最後執行的結果。在小型的clusters(~40 nodes),單一實體主機可能同時兼具多重node腳色,如Name Node及Job Tracker。中大型的clusters中,通常單一實體主機則只會扮演一種腳色。

Hadoop Cluster
上圖是Hadoop Cluster的典型架構。在每個機架內有多部的機架式伺服主機(非刀片式主機),經由1GE或2GE的網路連至機架頂端的交換器(TOR),每個TOR再uplink到上層的交換器。Cluster中大部分都是配置大容量硬碟的slave nodes主機,master nodes主機配置的local disk一般比較salve node小,但CPU、DRAM的需求比slave nodes來的大。
Hadoop Workflow
為何要建置Hadoop? 它可以解決甚麼問題? 簡單地說,假設企業或政府有非常龐大的數據,需要加以分析,並且要能快速地處理。如果能夠將龐大的數據切分成許多的小數據塊(block),並將它分散到許多機器上,並讓所有機器同時處理它所負責的部分,那麼就能快速的得到答案。舉個例子,你要存放100箱書籍並快速統計所有書籍數量。你不須準備一個大倉庫,你可以將它分散到10個小倉庫,並要求每個倉庫管理員將統計結果回報給你,那麼你就能快速得到所有書籍的數量。而這就是Hadoop的概念。模擬一個情境來簡單了解Hadoop的運作:有一個龐大的數據檔案,裡面包含了顧客寄給客服部門的email。我想要快速統計這些email裡面"refund”這個字出現多少次,以協助退換貨部門做出適當的因應處理。
在這個簡單統計字詞的次數的情境中,Hadoop Client將資料(File.txt)載入到 cluster,並送出如何統計分析資料的需求描述(word count),cluster將結果儲存到一個新的檔案(Results.txt),最後Client讀取檔案得到最後的結果。

檔案寫入到 HDFS
要將大數據檔案File.txt載入到cluster,client先將檔案分成許多小數據塊(block),然後將這些block分散到cluster中不同的主機上。block越多,就表示有更多的主機可以平行處理這些數據。為避免存放數據的主機發生故障,導致數據遺失,所以需將每一個數據塊存在於多台主機上。Hadoop標準設定是將每個block在clsuter中複製3份。這可在hdfs-site.xml檔案的dfs.replication參數進行設定。Client將File.txt分成3個block,client先詢問Namenode(通常是 TCP 9000)並收到可存放的Datanode清單。接著,client直接將block寫入到Datanode(通常是 TCP 50010)。Datanode再將block複製到其他的Datanode,重複直到所有的block均被寫入為止。Namenode不負責實際存放數據資料,Namenode僅提供數據存放在那些data node的對應資料(file system metadata)。

Hadoop Rack Awareness(機架感知)
Hadoop有項概念稱為"機架感知(Rack Awareness)”。Hadoop系統管理員可自行設定cluster中每個Datanode的機架號碼。主要有兩個理由:防止數據遺失,及網路效能。前面曾提過,每個block都有副本存放在其他的主機上以防止數據遺失。假設一個情況,存放相同數據副本的主機都位在同一的機架。很不幸的機架發生故障,可能是機架電源出狀況或是網路交換器(TOR)故障,這將導致部分的數據遺失。為避免此狀況,Namenode必須了解Datanode存在於網路拓譜(Network topology)中的位置,並智能判斷副本數據應該存放在哪裡。
在網路傳輸部分,同一個機架中的兩部主機比起不同機架的兩部主機,相互之間應該有更多頻寬與低延遲(lower latency)的優點。機架交換器的上行(uplink)頻寬通常小於下行(downlink)頻寬,而且機架內的網路延遲(latency)會小於機架之間。
想要Hadoop的機架感知功能在保護數據的同時又能優化網路傳輸、提升網路效能。系統管理者必須在一開始就做好完整的架構規劃,手動維護每個datanode的機架號碼等設定與對應資訊,並且需要持續更新,保持資訊的正確性。
有項新的網路技術 OpenFlow。在OpenFlow網路架構中,Name Node可以向OpenFlow controller詢問各節點在網路拓譜中的位置,這將減少系統管理者的許多工作,並提高Hadoop cluster運作的可靠性與效能。

Preparing HDFS Writes
Client準備將已經被切成許多block的File.txt載入到cluster,先從block A開始。client告知Namenode要寫入File.txt,然後得到Namenode的許可,並收到每個block對應Datanode的清單。Namenode利用機架感知功能來決定哪些Datanode最適合用來儲存這些block的數據,副本存放主要的規則是,對於每個block,有2份副本存放在相同的機架,另一份副本則放在其他的機架。在client要將block A寫入cluster之前,必須先知道所有預備接收數據的Datanode已經準備好了。從清單中選擇block A的第一個Datanode(Datanode 1),開啟TCP 50010的連接,並傳送"嗨,準備接收block,另有2個Datanode,Datanode 5跟Datanode 6,也一併確認已經準備好接收block”。接著Datanode 5就問Datanode 6,"嗨,準備好接收block了嗎?"
準備就緒的回應訊息使用相同的TCP傳輸路徑回傳,直到Datanode 1回送"ready”的訊息到client。這時,client才開始將block的數據寫入cluster。
關於數據副本規則已有更改:圖示及說明為Hadoop 1.2的架構。在Hadoop 2.3的架構中,以一般常見存放3份副本為例,第一份副本放在本地機架的節點,第二份放在本地機架的不同節點,最後一份放在不同機架的不同節點。
參見:HDFS Architecture

HDFS Write Pipeline
每個block在被寫入到cluster的時候,儲存數據副本的3個Datanode之間的傳輸路徑已經建立。這表示Datanode在收到block數據的同時,也將副本數據傳輸到下一個Datanode。這是一個利用Namenode的機架感知功能來提高cluster性能的主要例子。請注意,在傳輸路徑中的第二和第三Datanode都在同一機架中,因此,數據最後一次的傳遞不需要在跨機架之間傳輸,數據在同機架內傳輸可達到高頻寬及低延遲的網路效益。直到該block被成功寫入所有三個節點,才會開始將下一個block的寫入作業。
圖示及說明為Hadoop 1.2的架構。Hadoop 2.3的架構已有更改。

HDFS Pipeline Write Success
當全部3個Datanode都成功收到block數據以後,會送給Namenode一份"block received"的報告,也會經由建立的TCP session回傳"success"的訊息。client收到傳輸成功的訊息後會通知Namenode,block已寫入完成。然後Namenode更新metadata的資料,紀錄實際存放File.txt的block A的node位置。直到此時,一個block的寫入作業才算完成。client可以開始傳輸下一個block的數據。

HDFS Multi-block Replication Pipeline
File.txt的block循序被寫入的過程裡,每個傳輸路徑的初始節點可能不盡相同,cluster當中遍佈著同機架與跨機架的副本資料數據傳輸流量。Hadoop會耗用大量的網路頻寬和存儲硬體。通常都用來處理TB起算的超大檔案,而且每個檔案都會被複製到網路和磁碟3次。所以如果有一個1TB的檔案,它會耗用網路流量3TB用來完成傳輸檔案,以及3TB的磁碟空間來保存檔案。

Client Writes Span Cluster
在每個block的複製路徑完成後,檔案被成功寫入到cluster。如所預期的檔案被以block的方式散佈在cluster的主機裡,每台主機都有著相關聯的小部分數據。檔案由眾多的block組成,更多的主機意味著可將數據散佈的更廣。更多的CPU內核和存放數據的磁碟意味著更多的並行處理能力和更快的運算結果。這是驅使建構更大、更寬的cluster的動機。為能更多更快處理的數據,當主機數量變多和cluster變寬,網路架構也需要適當擴展。另一種擴充cluster的方式是"go deep”,以擴充主機CPU的內核以及硬碟容量(數量)的方式取代擴充主機數量。採此擴充方式,因為每部主機的儲存容量變得更大,相對網路I/O將變得更頻繁,頻寬的需求也變得更高。是否採用更高速的傳輸網卡或10G交換器,是一項值得考慮的事。

Name Node
Namenode掌管cluster所有檔案系統的metadata,並監督Datanode的存活狀態及協調數據的存取。Namenode是HDFS的中央控制中心,自身並不儲存檔案數據,只知道某個檔案是由那些block組成,而那些block又存放在cluster的那個位置(Datanode)。Namenode指引client需要跟那些Datanode聯繫,追蹤紀錄cluster儲存空間的容量,每個Datanode的存活狀態,及確保每個block的數據副本都遵循系統的設定規範存在。Datanode每3秒經由TCP handshark向Namenode傳送heartbeat訊息,一般使用與Namenode daemon相同的port number(TCP 9000)。每10次的heartbeat傳送block report,告知Namenode全部儲存的block有哪些。block report協助Namenode建構完整的metadata及確保每個block都存在著3份副本數據,並在不同的機架中。
Namenode是HDFS的關鍵構件。沒有它,client將無法讀寫HDFS的檔案,也就不可能排定執行Map/Reduce的工作。因此,應考量以企業等級的硬體架構建置Namenode,如雙電源供應器、熱抽換風扇、備援網卡(NIC)等。

Re-replicating Missing Replicas
如果Namenode沒有在一定的時間內收到從Datanode傳來的heartbeat訊號,它會假定該Datanode已經掛了,而且該Datanode所儲存的數據也不見了。基於之前從這個故障Datanode所收到的block report,Namenode知道有那些block已跟隨著這個Datanode消失不見了,並決定如何重新複製這些副本數據到其他的Datanode。它依據機架感知功能,並遵循著2份副本數據存在同一個機架,另1份副本數據存在其他機架的原則,來決定哪些Datanode應該接收block的新副本。考慮如下場景:整個機架的主機全掛了,這可能是機架交換器(TOR)故障或是電源出狀況所造成。Namenode將開始指示cluster中剩餘節點重新複製所有在該機架中丟失的block數據。如果機架中的每部主機有12TB的數據,這表示可能有幾百TB的數據量在網路間傳輸。因此,在設計Hadoop cluster架構時,應儘量避免機架故障的情形發生。

Secondary Name Node
Hadoop有所謂的第二Namenode的主機伺服器角色。一個常見的誤解是,這個角色提供了Namenode一個高可用性的備份。可惜,並不是。第二Namenode定時會連接到Namenode(默認情況下,每小時),抓取Namenode內存中的metadata和存儲metadata的檔案(這兩者可能會不同步)的副本。第二Namenode結合這兩部分的資訊組成一份全新檔案,並將這些檔案回傳到Namenode,同時本身保存一份副本。
當Namenode掛點了,第二Namenode所保留的檔案可以用來復原Namenode。在繁忙的cluster中,系統管理員應設定第二Namenode的備份頻率,更頻繁地提供此清理服務。或許可設定為每分鐘一次。

Client Read from HDFS
當client想從HDFS中取出檔案,也許是Map/Reduce工作的輸出檔,它會再次諮詢該Namenode並要求檔案的block所在的位置(Datanode),Namenode會回傳每個block被存放的Datanode的清單。客戶從每個block清單中挑選一個Datanode,使用TCP端口50010一次讀取一個block,這是Datanode daemon的默認端口。在block未完成讀取前,不會進行讀取下一個block的動作。

Data Node reads from HDFS
有些情況是,某個Datanode被要求對數據進行處理作業(通常是Map job),但Datanode daemon在讀取HDFS的block數據時卻發現不在本地的硬碟上,因此它必須透過網路從另一個datanode讀取數據來進行處理。nodenode的rack awareness技術運用的另一個重要的例子是能提供最佳的網絡行為。當Datanode要求Namenode提供block數據的位置,Namenode會檢查是否在同一機架的其他Datanode有此數據。如果是,Namenode則提供此位置給要求的Datanode。好處是,取得block數據的網路路徑不須跨交換器或其他網路設備,傳輸路徑最短。這表示,越快取得要處理的數據,就能越快完成數據處理的工作。

Map Task
現在File.txt已被切分成許多個小block並分佈在cluster的主機中,有機會以極其快速和高效的並行處理它。Hadoop的並行處理框架(framework)稱為Map Reduce,名稱中包含了兩個重要步驟:Map和Reduce。第一步是Map作業。這是同時要求主機對本地磁碟中的block數據執行運算。在這模擬情境中,我們要求我們的主機在File.txt的block數據中計算出現“Refund”的次數。
此個過程一開始,client提交Map Reduce作業給Job Tracker(通常與Namenode同主機),問說:“在File.txt中Redund這個字出現幾次”(這段為Java code的翻譯)。Job Tracker諮詢Namenode以了解哪些Datanode有File.txt的block數據。Job Tracker接者提供執行Map運算的Java code給那些在Datanode上的Task Tracker。Task Tracker開始Map作業並和監視任務的進度。Task Tracker將heartbeat訊息和任務狀態回應給Job Tracker。
每個Map任務完成後,每個節點將本地運算的結果存儲在本地暫存磁碟空間,此稱為“中間數據(intermediate data)”。下一步是通過網路把"中間數據"傳送給執行最後計算的Reduce任務的節點。

What if Map Task data isn’t local?
儘管Job Tracker會盡量挑選本地存有block數據的節點執行Map任務,但可能會有例外發生。其中一個原因可能是,所有本地存有block數據的節點已經運行了太多其他的任務了,無法再接受新任務。在這種情況下,Job Tracker將徵詢Namenode,運用Rack Awareness的原理建議在同機架的其他節點。Job Tracker將分配任務給在同一個機架的節點,Namenode會指引該節點向同機架的其他節點拿到所需的block數據,利用同機架交換器的單點傳輸路徑與高頻寬特性提升效能。

Reduce Task computes data received from Map Tasks
Map Reduce framework 第二階段稱為Reduce。主機上的Map任務完成後並產生中間數據。現在,需要將所有這些中間數據結合起來歸納整理後,以提供其進行進一步的處理獲得個最終的結果。Job Tracker在cluster中任一個節點開始Reduce任務,並指示Reduce任務去抓取所有Map任務完成後的中間數據。Map任務有可能同時回應給Reducer,造成一種情況,多個節點同時傳送TCP數據到同一個節點。此網路流量狀況通常被稱為“Incast”或“fan-in”。對於網絡處理大量的incast狀況,其重要的網路交換機需有精心設計的內部流量管理能力,和足夠的緩衝區(不要太大,不要太小)。在交換器上投入大量的緩衝區最終可能會對網路流量造成不必要的附家損害。但是,這是另一個話題。
Reducer任務在收集了所有Map任務的中間數據後,開始最後階段的計算作業。在此模擬情境中,我們簡單地加總出現“Refund”這個詞的次數,並將結果寫入到一個名為Results.txt檔案。
任務最後輸出到一個名為Results.txt檔案,該檔案被寫入到HDFS中,寫入程序如前面所提,將檔案分割為許多block,分散儲存到Datanode中,並完成副本儲存。一切完成後,client可從HDFS中讀取Results.txt檔案,此作業才可視為完成。
此簡單的字數統計工作並未導致大量的中間數據在網絡上傳輸。但其他的工作可能會產生大量的中間數據,例如排序1 TB數據的工作。其中Map Reduce工作結果是一組新的數據,等於數據處理前的大小。Map Reduce作業中會產生多少網路流量,完全依賴於運行的作業類型。
如果你是一個好學的網絡管理員,你會了解到更多的不同類型的Map Reduce作業對網絡上的流量的影響。如果你是一個網絡Hadoop的搖滾明星,你甚至可以建議如何編寫更好Map Reduce作業代碼,以優化網絡的性能,從而加快工作完成時間。

Unbalanced Hadoop Cluster
Hadoop可能會在組織中成功運作,從所有數據中提供了很多以前未開發的商業價值。當業務人員了解這一點,你可以打賭,你很快就會有更多的錢為Hadoop cluster購買主機和網絡機架。當你往Hadoop cluster中添加塞滿主機的機架時,將導致cluster不平衡的情況。在這種情況下,機架1跟2是現有的機架,含有File.txt和運行的Map Reduce程序。當我添加了兩個新的機架到cluser中,File.txt的數據不會自動奇蹟般地重新開始分布到新的機架。所有的數據都留在原來的地方。
新的主機因為沒有數據所以處於閒置狀態,直到開始將新的數據加載到cluster中。此外,如果在機架1和2中的主機都非常繁忙,Job Tracker可能沒有其他選擇,只能把運算File.txt的Map任務指派到沒有儲存File.txt數據的新主機。所以,新的主機需要透過網路抓取數據,結果可能是造成更多的網絡流量和較慢的工作完成時間。

Hadoop Cluster Balancer
要解決cluster不平衡的情況下, Hadoop包含一個極好的工具,叫做balancer。Balancer觀察所有節點的可用儲存空間之間的差異,並試圖將其平衡維持在一特定的臨界值。新節點會被檢查到有很多的空閒磁盤空間,於是balancer開始將可用空間過少的節點的block數據複製到新節點。除非有人在終端前下命令,否則balancer不會自動運行,當終端取消或關閉時則停止運行。
balancer可以使用網絡流量的量是非常低的,默認設置是1MB/s。修改hdfs-site.xml 設定檔的dfs.balance.bandwidthPerSec參數可變更此設定。
balancer是cluster中很好的助手。當增加新主機時絕對要使用它,甚至每週應執行一次。鑑於balancer預設的低頻寬設定,可能需要很長的時間才成完成平衡的工作,也許幾天或幾週。
訂閱:
意見 (Atom)